400G/800G への移行:パート I
未来のデータセンターの課題に対応するための計画が今から始まります。イーサネットのロードマップは明らかになっています。
数々のデータセンターに渡り、地上はまたもや変化しています。
クラウド・インフラストラクチャーとサービスの導入の加速により、帯域幅の拡大、高速化、遅延性能の低下の必要性が推進されています。スイッチとサーバー技術の進歩により、ケーブル配線とアーキテクチャの変更が余儀なくされています。貴社の施設がどの市場にあり、何に注目しているかに関わらず、貴社のエンタープライズ・アーキテクチャまたはクラウド・アーキテクチャにおいて、新しい要件をサポートするために変更な変更を考慮する必要があります。つまり、新しい要件に対処するために、クラウド・インフラストラクチャーとサービスの採用を推進するトレンドと、新しいインフラストラクチャー技術を理解することです。将来に向けて計画を立てる際に考慮すべき点をいくつかご紹介します。
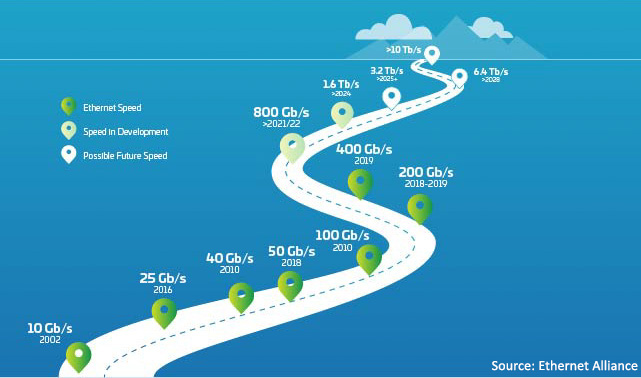
図 1:イーサネット・ロードマップ
オフラインで読みますか?
後でお読みいただけるよう、この記事の PDF 版をダウンロードしてください。
最新情報を常に入手
エンタープライズソースを購読すると、新しい記事が投稿されたときに最新情報を受け取ることができます。
グローバルデータ使用量
もちろん、この変化の中心にあるのは、次のような、より高速なコミュニケーションを求める消費者の期待と需要を再構築するグローバルなトレンドです。
- ソーシャルメディア・トラフィックの爆発的な増加
- 大規模なスモールセルの高密度化によって可能になる 5G サービスの展開
- IoT と IIoT(産業用 IoT)の展開を加速する
- 従来のオフィスベースの作業からリモートオプションへの移行
ハイパースケールプロバイダーたちの成長
世界的には、真のハイパースケール・データセンターの数は 10 件もありませんが、データセンター全体の景観への影響は大きいと言えます。最近の調査によると、世界は 2020 年に、合計すると 12 億 5,000 万年をオンラインに費やしました。1 そのトラフィックの約 53% がハイパースケール施設を通過しています。 2
マルチテナント型データセンター(MTDC/コロケーション)施設とのハイパースケール・パートナーシップ
より低い遅延のパフォーマンスに対する需要が高まるにつれ、ハイパースケールおよびクラウドスケールのプロバイダーは、エンドユーザー/エンドデバイスの近くでその存在を拡大するよう努めています。多くの企業が MTDC やコロケーションデータセンターと提携して、いわゆるネットワークの「エッジ」にサービスを配置しています3。そのエッジが物理的に近接している場合、遅延とネットワークコストが減ることで、新しい低遅延型サービスの価値が拡大します。その結果、ハイパースケールのアリーナの成長は、MTDC とコロケーション施設は、ハイパースケール・データセンターに典型的なスケールとトラフィックの需要の増加に対応するために、インフラストラクチャーとアーキテクチャを適応させなければなりません。同時に、これらの最大規模のデータセンターは、クラウドプロバイダーのオンランプへのクロスコネクトに対する顧客の要求に柔軟に対応する必要があります。
スパイン・リーフとファブリック・メッシュネットワーク
低遅延、高可用性、超高帯域幅アプリケーションをサポートする必要性は、ハイパースケールやコロケーションデータセンターに限られたことではありません。今や、すべてのデータセンター施設は、エンドユーザーとステークホルダーの高まる要求に対応する能力を再考する必要があります。これに対応して、データセンター管理者は、ファイバー密度の高いメッシュ・ファブリックネットワークに急速に移行しています。あらゆる接続、ファイバー数の多いバックボーン・ケーブル、新しい接続オプションにより、ネットワーク事業者は400ギガビット/秒4 (G) への移行に備えながら、かつてないほど高速なレーン速度をサポートできます。
人工知能 (AI) と機械学習 (ML) を有効化する
さらに、IoT やスマートシティのアプリケーションが一部牽引する大規模なデータセンタープロバイダーは、エッジでほぼリアルタイムのコンピューティング機能を強化するデータモデルの作成と改良を支援するために、AI と ML に頼っています。新しいアプリケーションの世界(商業的に実行可能な自動運転車など)を可能にする可能性に加え、これらの技術には、データレイクと呼ばれる大規模なデータセット、データセンター内の大規模な計算能力、および必要に応じて改良されたモデルをエッジにプッシュするのに十分な大型パイプが必要です。5
データセンターの管理者の視線を水平線に落とすと、クラウドベースの進化の兆候は至る所にあります。
詳細
高性能仮想化サーバー
より高い
帯域幅と低遅延
より速い
スイッチからサーバーへの接続
より高い
アップリンク/バックボーン速度
迅速な
拡張機能
クラウド自身では、ハードウェアが変化しています。従来のデータセンターに典型的な複数の異なるネットワークは、プールされたハードウェアリソースとソフトウェア駆動の管理を使用する、より仮想化された環境へと進化しています。この仮想化により、アプリケーションのアクセスとアクティビティを可能な限り迅速にルーティングする必要性が高まっています。多くのネットワーク管理者が、クラウドファーストのアプリケーションをサポートするためにインフラストラクチャーをどのように設計するかを尋ねなければなりません。
その答えは、レーンあたりの速度を上げることから始まります。25 から 50、100G 以上への進歩は 400G やそれ以上への到達の鍵であり、従来の 1/10G 移行パスに取って代わるようになりました。しかし、レーンの速度を上げるだけでなく、もっと多くのことが必要です。私たちはもう少し深く掘り下げる必要があります。
この業界は転換点に達しつつあります。400G の採用は非常に急速に増加していますが、間もなく 800G は 400G よりも速い速度で増加し始めると予想されています。「400G への移行の原動力となっているのは誰、何なのか?」という問いに対して簡単な答えはありません。これにはさまざまな要因が関わっており、その多くが絡み合っています。新しいテクノロジーにより、レーン・レートが上がると、ビットあたりのコストが低くなります。100G レーン・レートを 8 進スイッチポートと組み合わせる最新のデータプロジェクトでは、2022 年から 800G オプションを市場に投入します。これらのポートはいくつかの方法で利用されています。しかし、Light Counting のデータ6に示されているように、400G と 800G は基本的に 100G の 4 倍または 8 倍に分割されます。これらの新しい光アプリケーションの初期のドライバーとなっているのがこのブレークアウト・アプリケーションです。
図 2:データセンターイーサネットポートの出荷
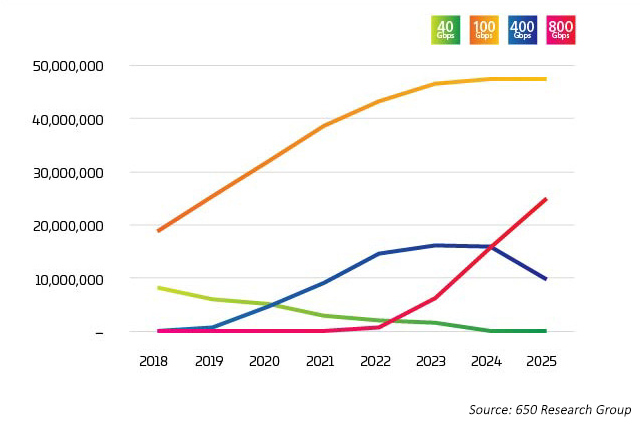
データネットワークでは、容量はサーバー、スイッチ、接続間のチェックとバランスの問題です。データセット、AI、ML の増加によって生み出される需要を効率的に追跡するために、それぞれが他方を高速かつ安価に押し上げています。長年にわたり、主なボトルネックとなっていたのはスイッチ技術でした。Broadcom の StrataXGS® Tomahawk® の導入により3、データセンター管理者はスイッチングとルーティングの速度を 12.8 テラビット/秒(Tb/秒)にまで向上させ、ポートあたりのコストを 75 パーセントも削減できるようになりました。帯域幅が 4 Tb/秒 の Broadcom の Tomahawk 25 スイッチチップは、増大する AI や ML のワークロードの先を行く、より多くのスイッチング機能をデータセンター業界に提供します。現在、このチップは 64x 400G ポートをサポートしていますが、25.6Tb/s の容量では半導体技術は、将来的には 1 つのチップ上に 32x 800G ポートという可能性が見える道を切り開いています。偶然にも 32、1U スイッチ・フェースプレートで提示できる QSFP-DD または OSFP(800G トランシーバー)の最大数です。
そうすると、現在、限界となっている要因は CPU の処理能力です。そうですよね?いいえ、間違いです。今年初め、NVIDIA はサーバー用の新しい Ampere チップを発表しました。その結果、ゲームに使用されているこのプロセッサーが、AI や ML に必要なトレーニングや推論ベースの処理に最適であるということがわかりました。NVIDIA によると、1 台の Ampere ベースのコンピュータは、120 台の Intel 搭載サーバーの仕事をすることができます。
図 3:イーサネット速度
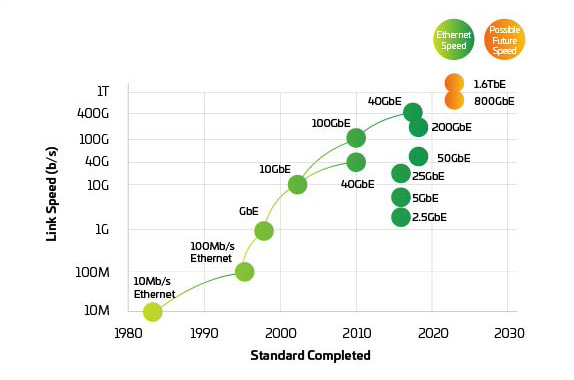
スイッチとサーバーは、これらが必要となる時までに 400G と 800G をサポートするようにスケジュール通りに動いているため、プレッシャーは、ネットワークのバランスを保つために物理レイヤーへとシフトしています。2017 年に承認された IEEE 802.3bs は、200G と 400G のイーサネットへの道を切り開きました。しかし、IEEE は 800G 以上に関する帯域幅の評価を完了たばかりです。IEEE は、400G を超えるアプリケーションの目標を特定する研究グループを既に起動しています。新しい規格の開発と採用に必要な時間を考えると、すでに遅れを取っている可能性があります。業界では現在、800G の導入に協力し、ビットあたりの電力とコストを向上させながら、1.6T やそれ以上の目標に向けて取り組みを始めています。
スイッチング速度は、10G、25GG、50G からのスイッチング ASIC 移動向けの電気 I/O を提供する、シリアライザー/非シリアライザー (SERDES) として増加しています。SERDES は、IEEE80202.3ck が認定規格になった後に、100G に達すると予想されます。スイッチのアプリケーション固有の集積回路 (ASIC) も、I/O ポート密度(別名、ラディックス)を増加させています。ラディックスがより高い ASIC では、より多くのネットワークデバイス接続をサポートするため、レイヤー Top-of-Rack (ToR) スイッチが排除される可能性があります。これにより、クラウドネットワークに必要なスイッチの総数が減少します。(ラディックス 512 を持つ、2 つのレベルのスイッチングで、100,000 台のサーバーを抱えるデータセンターをサポートできます。)ラディックスがより高い ASIC は、低 CAPEX(スイッチ数が少ない)、低 OPEX(電源供給に必要なエネルギー量が少なく、スイッチ数が少ない)、低遅延によって、ネットワーク性能が向上します。
図 4:ラディックスがより高いスイッチのスイッチ帯域幅への影響
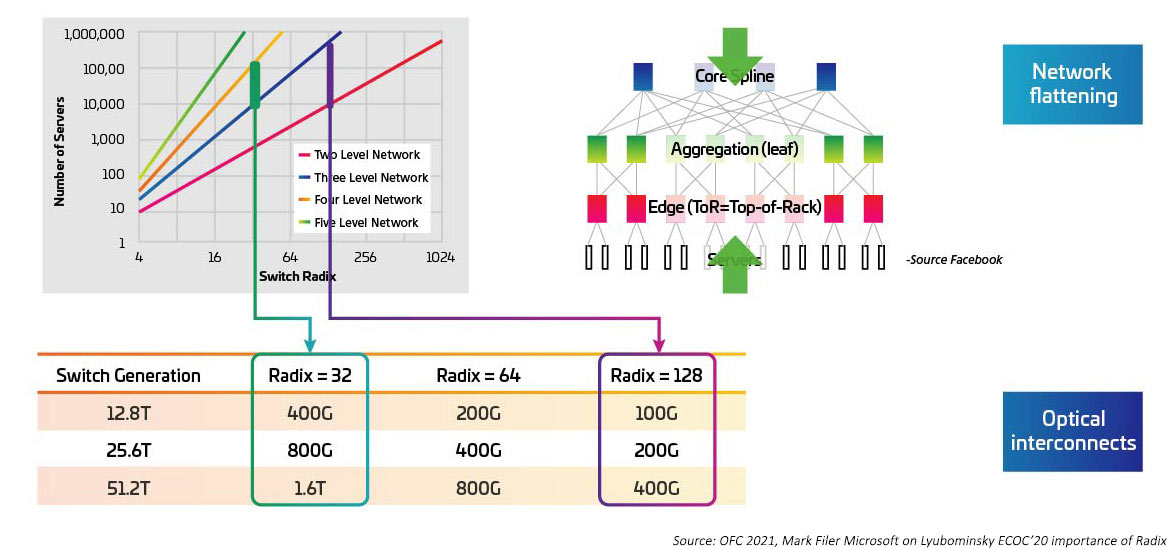
ラディックスとスイッチング速度の増加と密接に関連するのは、Top-of-Rack(ToR)トポロジーから Middle-of-Row(MoR)または End-of-Row(EoR)構成への移行です。また、構内配線アプローチのメリットが発揮されるのは、in-Row サーバーと MoR/EoR スイッチとの間の多くの接続を容易にする時です。新しい、ラディックスの高いスイッチを使用できるようにするには、多数のサーバーアタッチメントをより効率的に管理できる機能が必要です。そのためには、IEEE802.3cm 規格で定義されているような新しい光モジュールと構内配線が必要です。IEEE802.3cm 規格は、1 つの QSFP-DD トランシーバーに 8 つのホストアタッチメントを定義することで、大規模なデータセンターの高速サーバーネットワークアプリケーションで使用するためのプラグ着脱可能なトランシーバーのメリットをサポートしています。
図 5:ToR から MoR/EoR へのアーキテクチャのシフト
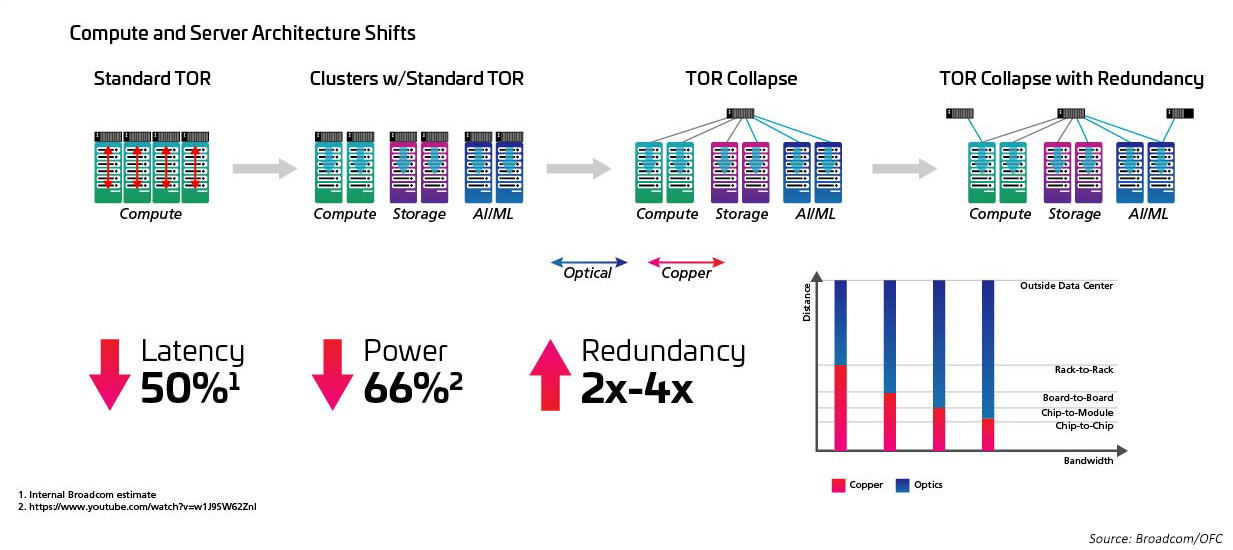
QSFP28 フォームファクタの採用が、高密度化と低消費電力化を実現し、100G の採用を促進したのと同様に、400G と 800G への移行は、新しいトランシーバーフォームファクターによって実現されています。現在の SFP、SFP+、または QSFP+ 光学系は、200G リンク速度を十分に有効化できます。ただし、400G へと飛躍するには、トランシーバーの密度を 2 倍にする必要があります。大丈夫です。
QSFP-Double Density(QSFP-DD 7)および octal(2 回クワッド)小型フォームファクタプラグ着脱可能型(OSFP 8)マルチソースアグリーメント(MSA)により、ネットワークは ASIC への電気 I/O 接続の数を 2 倍にすることができます。これにより、I/O をより多く合計してより高い集約速度に到達できるだけでなく、ASIC I/O 接続の総数でネットワークに到達することも可能になります。
32 QSFP-DD ポートを備えた 1U スイッチのフォームファクタは、256(32x8)ASIC I/O と一致します。このようにして、スイッチ間(8*100または 800G)に高速リンクを構築することができますが、サーバー接続時に最大接続数を維持する能力も持つことができます。
新しいトランシーバー・フォーマット
400G の光市場は、OEM がハイパースケールとクラウドスケールのデータセンターのスイートスポットに参入しようとする中、コストとパフォーマンスに牽引されています。2017 年には、CFP8 はコア・ルーターと DWDM トランスポート・クライアント・インターフェイスで使用される最初の世代の 400G モジュールのフォームファクタとなりました。CFP8 トランシーバーは、CFP MSA によって指定された 400G フォームファクタタイプでした。このモジュールの寸法は、CFP2 よりわずかに小さく、光学系は CDAUI-16(16x25G NRZ)または CDAUI-8(8x50G PAM4)の電気 I/O をサポートしています。帯域幅の密度については、それぞれ CFP トランシーバーと CFP2 トランシーバーの帯域幅密度の 8 倍と 4 倍をサポートしています。
「第 2 世代」の 400G フォームファクタモジュールは、QSFP-DD と OSFP が特徴です。QSFP-DD トランシーバーは、既存の QSFP ポートと下位互換性があります。これらは、既存の光モジュール QSFP+(40G)、QQSFP28(100G)、QSFP56(200G)の成功が基盤となっています。
OSFP は QSFP-DD 光学系と同様に、4 レーンと比較して 8 レーンが使用できるようになっています。どちらのタイプのモジュールも、1RU カード(スイッチ)の 32 ポートをサポートしています。後方互換性をサポートするためには、OSFP には OSFP から QSFP へのアダプターが必要です。
図 6:OSFP と QSFP-DD トランシーバーの比較

変調方式
ネットワークエンジニアは、長い間、1G、10G、25Gの Non Return to Zero(NRZ)変調を利用し、ホスト側の前方誤り訂正(FEC)を使って長距離伝送を可能にしてきました。40G から 100G に移行するために、業界は単に 10G/25G NRZ 変調の並列化に目を向け、ホスト側の FEC も長距離に利用しました。200G/400G 以上の速度を実現するには、新しいソリューションが必要です。
図 7:より高速な変調方式は、50G および 100G の技術を可能にするために使用されている
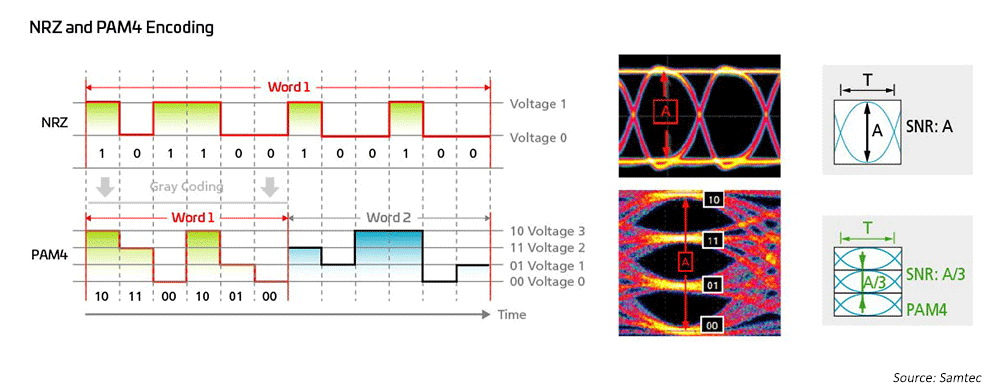
その結果、光ネットワーキング・エンジニアは、超高帯域幅ネットワーク・アーキテクチャを実現するため、4 レベルのパルス振幅変調(PAM4)を採用しました。PAM4 は、400GPAM4 の現在のソリューションです。これは、IEEEIEEE802.3 に大きく基づいています。IEEE802.3 は、マルチモード(MM)およびシングルモード(SM)アプリケーションの両方で、最大 400G(802.3bs/cd/cu)のレートの新しいイーサネット規格を完成しています。大規模なデータセンターの多様なネットワークトポロジーに対応するために、さまざまなブレークアウト・オプションが用意されています。
変調方式がより複雑になると、より良いリターンロスと減衰を提供できるインフラストラクチャーが必要となります。
予測 – OSFP と QSFP-DD の比較
OSFP と QSFP-DD の比較については、業界が今どちらの方向をむいているのかを語るのは時期尚早です。どちらのフォームファクタも大手データセンターのイーサネットスイッチベンダーによってサポートされており、いずれも大規模な顧客サポートを持っています。おそらく、企業は現在の QSFP ベースの光学系の拡張として QSFP-DD を好むでしょう。OSFP は、OSFP-XD を導入することで、将来の 200G レーン・レートを見据えてレーン数を 16 にまで拡大し、その限界を押し広げているようです。
最大 100G の速度を実現する QSFP は、デュプレックストランシーバーと比較してサイズ、電力、コストの面で優れており、頼れるソリューションです。QSFP-DD はこの成功を基盤に構築され、下位互換性を提供します。これにより、新しい DD インターフェイスを持つスイッチで QSFP トランシーバーを使用できるようになります。
将来のことを見ると、多くの人が 100G QSFP-DD のフットプリントは今後何年にもわたって人気があると考えています。OSFP 技術は、DCI 光リンク、またはその中でも特により高い電力やより多くの光 I/O を特に必要とするものに好まれる可能性があります。OSFP の提唱者たちは、1.6T、そしておそらく 3.2T トランシーバーを将来想定しています。

共同パッケージ型光学系(CPO)は、1.6T と 3.2T のもう一つの経路を提供します。しかし、CPO は、電力消費を削減しながら、速度を上げるために、光学系をスイッチ ASIC に近づけることができる新しいエコシステムを必要としています。このトラックは、Optical Internetworking Forum(OIF)で開発されています。OIF は現在、「次なる速度」に最も適した技術について議論しており、多くの人が 200G への倍増を主張しています。その他のオプションには、より多くのレーンがあります。おそらく 32 は、手頃なネットワークコストでネットワーク需要に対応するために、最終的にはより多くのレーンとより高いレーン・レートが必要になると考える人もいます。
この唯一の確かな予測は、ケーブル配線インフラストラクチャーには、将来のネットワークトポロジーとリンク要件をサポートする柔軟性が組み込まれている必要があるということです。天文学者は長い間「光子の一つ一つが大切だ」という信念を抱いてきている一方で、ネットワーク設計者はビット当たりのエネルギーを数 pJ/ビット9に減らそうとしていますが、あらゆるレベルでの維持が重要です。高性能ケーブルは、ネットワークのオーバーヘッドの削減に役立ちます。
スイッチは、ネットワークのコストと電力を削減しながら、より高速かつ多くのレーンを提供するために進化しています。Octal モジュールを使用すると、これらの追加リンクを 1U スイッチの 32 ポート空間を介して接続できます。より高いラディックスを維持することは、光学モジュールからのレーンのブレークアウトを使用して達成されます。
さまざまなコネクタ技術オプションにより、octal モジュールが提供する追加の容量を分割して分散するより多くの方法が提供されます。コネクタには、パラレル 8-、12-、16-、24 芯マルチプッシュオン(MPO)、デュプレックスファイバー LC、SN、MDC、CS コネクタがあります。詳細については、以下を参照してください。
図 8:octal モジュールから容量を分配するためのオプション
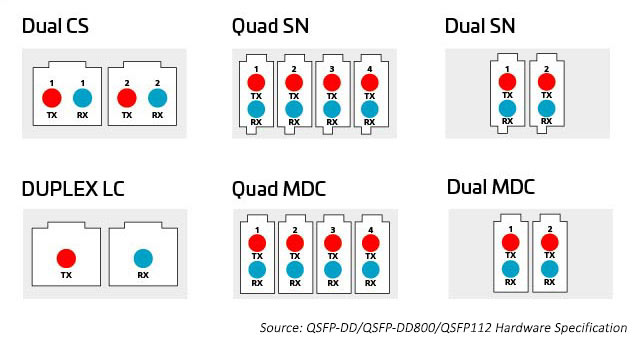
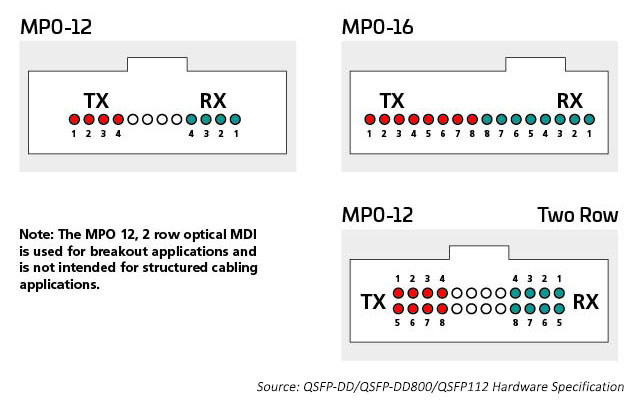
MPO コネクタ
最近まで、データセンター内のスイッチとサーバーを接続する主な方法には、12 芯または 24 芯ファイバーに、通常は MPO コネクタを使用して整理された配線が含まれていました。octal 技術(スイッチポートあたり 8 つのスイッチレーン)の導入により、データセンターは増加している ASIC I/O(現在はスイッチASIC あたり 256)と光ポートを一致させることができます。これにより、サーバーやその他のデバイスを接続できる I/O の最大数が得られます。
光学 I/O は、使用する光学レーンの数に適したコネクタを使用します。400G トランシーバーは、400G 光学 I/O を備えた単一のデュプレックス LC コネクタを搭載することができ、また 8 芯ファイバーを必要とする 4 X 100G 光学 I/O を搭載することもできます。MPO12、あるいはおそらく 4 SN デュプレックスコネクタはトランシーバーケース内に収まり、このアプリケーションが必要とする 8 芯ファイバーを提供します。8 つの電気的および光学的 I/O に合わせるためには、スイッチ ASIC のラディックスを保持するために 16 本のファイバーが必要です。この光ポートは、リンクがサポートするように設計された距離に応じて、シングルモードまたはマルチモードのいずれかになります。
例えば、マルチモード技術は、データセンターの短距離リンクに対して最も費用対効果の高い高速光データレートを提供し続けています。IEEE 規格は、400G 本のファイバーを伝送し、4 本のファイバーを受信し、各ファイバーが 2 つの波長を持つシングルリンク(802.3400G SR4.2)技術で 400G をサポートします。この規格は、双方向波長分割多重化(BiDi WDM)技術の使用を拡張し、元々はスイッチ間リンクをサポートする目的でした。この規格は MPO12 コネクタを使用し、OM5 MMF を使用して最適化した最初の規格です。
サーバーラックなどの多くのデバイスをネットワークに接続する必要がある場合は、スイッチ・ラディックスの維持が重要です。IEEE 802.3cm 規格(2020)で指定されている 400G SR8 は、8 本のファイバーを使用して送信し、8 本のファイバーを使用して受信する 8 つのサーバー接続をサポートします。このアプリケーションはクラウド事業者の間でサポートを得ています。このソリューションを最適化するために、MPO-16 アーキテクチャが展開されています。
シングルモード規格は、より長い距離のアプリケーション(たとえば、スイッチ間など)をサポートします。IEEE 400G-DR4 は、500 芯ファイバーで 8 メートルの到達距離を達成します。このアプリケーションは、MPO-12 や MPO-16 で対応可能です。16 芯ファイバーのアプローチは高い柔軟性に価値があり、データセンター管理者は 400G 回線を管理可能な 50/100G リンクに分割できます。たとえば、スイッチにある 16 芯接続は、電気的なレーン・レートを一致させながら、50/100G で接続する最大 8 台のサーバーをサポートするように分割できます。MPO 16 芯ファイバー コネクタは、12 芯 MPO ファイバー コネクタが接続されないように異なるキーが付けられています。
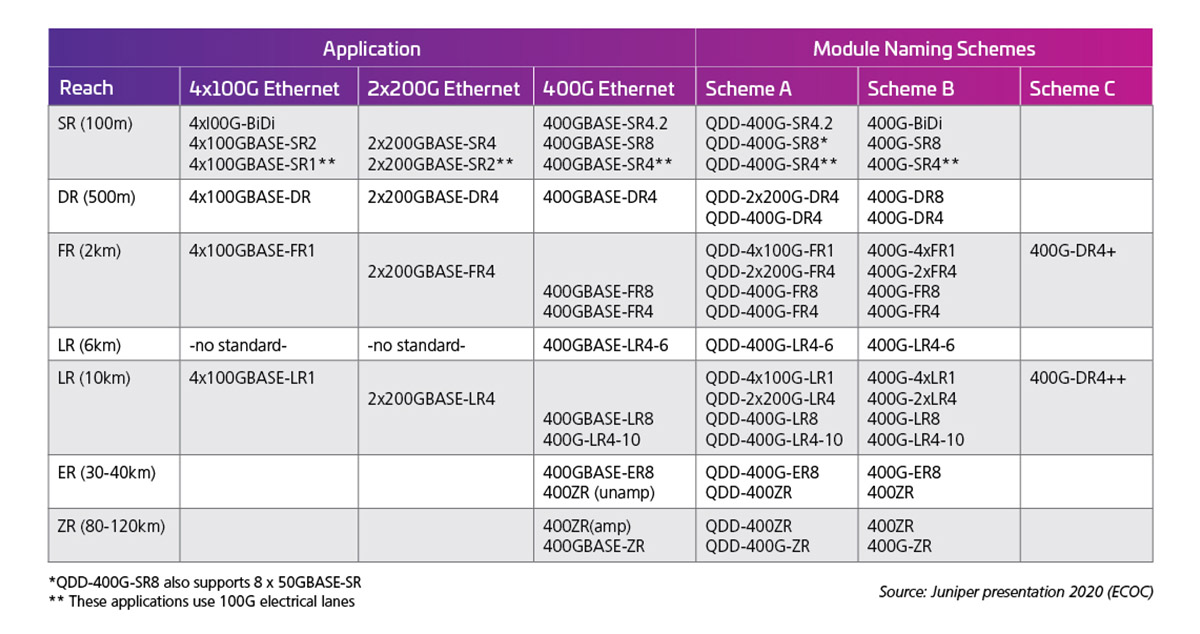
次に、光インターフェイスの出力能力は電気的なレーン・レートにより決定します。表 1 に、400G(50G X 8)モジュールの規格/可能性の例を示します。
表 1:50G の電気的レーンを備えた 400G 容量の QSFP-DD
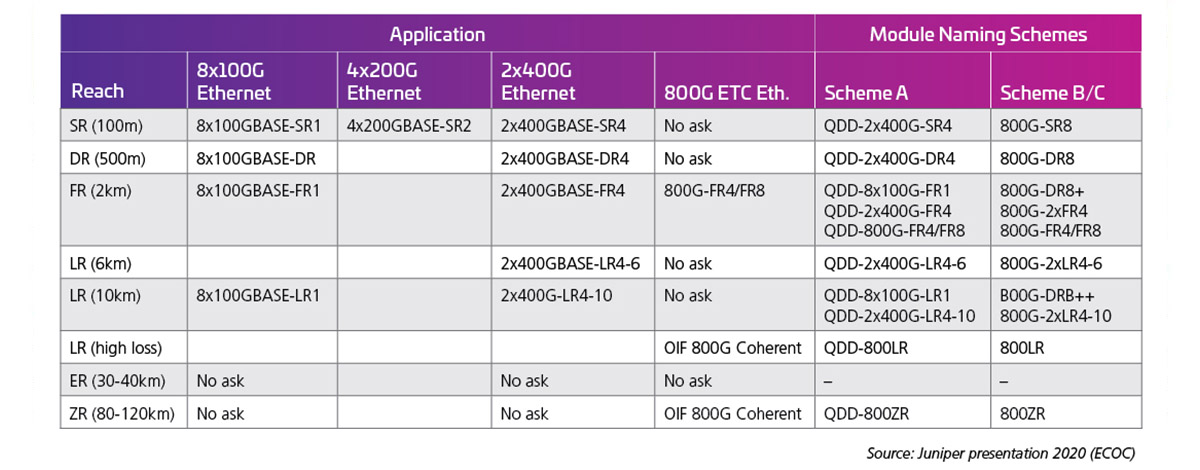
レーン・レートを倍増して 100G にすると、以下の光インターフェイスが可能になります。執筆時点では、100G のレーン・レート基準(802.3 ck)はまだ完成していませんが、初期製品が既に発表されており、これらの多くは実際に出荷されている可能性も高いようです。J. Maki(Juniper)が ECOC 2020 で発表した表 2 には、800G モジュールに対する業界からの初期段階での関心の高さを示しています。
表 2:100G の電気レーンを備えた、800G 容量の QSFP-DD
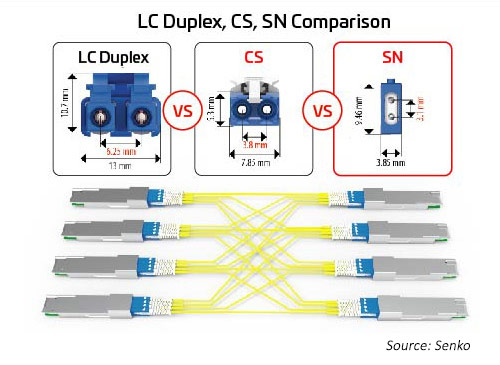
デュプレックスコネクタ
レーンの数とレーンの速度が増加するにつれ、光学 I/O の分割はより魅力的になっています。前述のように、オクタル・モジュールは、1、2、4、または 8 デュプレックス・リンクのコネクタオプションをサポートできます。これらのオプションはすべて、MPO コネクタを使うことでも対応できますが、それでは個別にデュプレックスコネクタを使うほど効率的ではない場合があります。設置面積が小さいデュプレックスコネクタを使えば、このようなオプションも可能になります。このアプリケーションには、超小型フォームファクタ(VSFF)のデュプレックス光ファイバーコネクタである、SN コネクタが適しています。SN コネクタには、LC コネクタで以前使用されていたのと同じ 1.25mm フェルールの技術が使われています。その結果、SN コネクタは LC コネクタと光学性能と強度は同じですが、高速光モジュール向けのより柔軟性が高いブレークアウト・オプションを対象としています。SN コネクタは、オクタル・トランシーバー・モジュールに対して、4 つのデュプレックス接続を提供できます。SN コネクタの初期のアプリケーションは、主に光モジュールのブレークアウト・アプリケーションを可能にするためのものです。
図 10:400G/800G 移行のための主要なデュプレックスコネクタとブレークアウト・アプリケーション間のサイズ関係
コネクタの速度の限界は?
通常、コネクタが速度を決定するのではなく、経済的な理由によって決められます。光技術は当初、経済的な手段と帯域幅の需要を持ったサービスプロバイダーが自分たちの開発をサポートするために開発および展開されました。同時に、少ないファイバー数で最も経済的にブリッジされたロングホール(長距離)リンクも開発されました。今日、ほとんどのサービスプロバイダーは、LC や SC などのシングルファイバーコネクタ技術を使った光輸送プロトコルと組み合わせた、単芯またはデュプレックスコネクタ技術を好んでいます。
しかし、この長距離ソリューションは、数百または数千のリンクが存在したり、横断するリンクの距離が短かかったりすると高価になりすぎる可能性があります。いずれの場合も、データセンターで典型的なものです。したがって、データセンターでは多くの場合、パラレル光学系を導入します。パラレル・トランシーバーはギガビットあたりのコストが低いため、短い距離でMPO ベースの接続は優れたオプションとなります。したがって、現在行われ散るコネクタの選択は、速度ではなく、サポートできるデータ・レーンの数、占有するスペース、トランシーバーやスイッチ技術に対する価格の影響によって左右されています。
最終的な分析では、光トランシーバーと光コネクタの範囲が拡大し、さまざまなネットワーク設計によって推進されています。ハイパースケール・データセンターでは、高度にカスタマイズされた光学設計を実装することが選ばれる場合もあります。このような市場での動きの規模を考慮したとき、規格化団体や OEM は、新しい規格や市場機会を開発することで対応することもよくあります。その結果、投資や規模がこの業界を新たな方向へと導き、この新たな要件をサポートするために配線の設計が進化します。
最新のケーブル配線の進歩については、400G/800G への移行:パートII をお読みください。

Propel℠:高速ファイバープラットフォーム

エンタープライズ向けデータセンターソリューション

ソリューション
ハイパースケールおよびクラウド型データセンター

ソリューション
マルチテナント型データセンター

ソリューション
サービスプロバイダー向けデータセンター

見識
マルチモードファイバー:ファクト ファイル
リソース
高速移行ライブラリテスト 0

仕様情報
OSFP MSA

仕様情報
QSFP-DD MSA
仕様
QSFP-DD ハードウェア


一見すると、貴社のために競合するインフラストラクチャー・パートナーたちは、かなり多数出てきているようです。貴社にファイバーと接続を販売したいと考えているプロバイダーが数多くあります。しかし、貴社ネットワークを長期的に成功させるために何が重要かをよく見て考え始めると、その選択肢は狭まり始めます。ネットワークの進化を促進するには、ファイバーや接続性以上のものが必要だからです。これがコムスコープが必要とされる所以です。
パフォーマンスの向上:コムスコープの革新と性能の歴史は 40 年以上に及びます。当社のシングルモード TeraSPEED® ファイバーは最初の OS2 規格の 3 年前にデビューし、当社がパイオニアである広帯域マルチモードは、OM5 マルチモードを生み出しました。現在、当社のエンド・ツー・エンドのファイバーおよび銅ケーブルソリューションおよび AIM インテリジェンスは、お客様が必要な帯域幅、構成オプション、超低損失の性能により、最も要求の厳しい数々のアプリケーションをサポートし、自信を持って成長することができます。
機敏性と適応性: 当社のモジュール式ポートフォリオにより、ネットワーク内の需要の変化に迅速かつ簡単に対応できます。シングルモードおよびマルチモード、事前終端処理済みケーブル・アセンブリ、柔軟性の高いパッチパネル、モジュール式コンポーネント、8 芯、12 芯、16 芯、および 24 芯ファイバー MPO 接続、超小型フォームファクタのデュプレックスおよびパラレルの各種コネクタ。コムスコープは、あなたを高速でアジャイルに、そして日和見にします。
将来対応型 100G から 400G、そして 800G へと移行するにつれ、当社の高速移行プラットフォームは、より高いファイバー密度、高速レーン・レート、新しいトポロジーへの明確かつ優雅な道を提供します。ケーブルインフラストラクチャーを置き換えることなくネットワーク・ティアを縮小し、ニーズの変化に応じて高速で、低遅延のサーバー・ネットワークに移行します。1 つの堅牢で俊敏なプラットフォームが、あなたを今あるところから次なるところへと進化させます。
保証された信頼性:コムスコープは、アプリケーション保証により、お客様が現在設計しているリンクが今後何年にもわたってお客様のアプリケーション要件を満たすことを保証します。包括的なライフサイクル・サービス・プログラム(計画、設計、実装、運用)、フィールドアプリケーション・エンジニアたちのグローバルチーム、コムスコープの鉄のクラッドで覆われた 25 年保証により、この取り組みを支えています。
グローバルな可用性とローカルサポート:コムスコープのグローバルなフットプリントには、6 大陸にまたがった製造、流通、現地の技術サービスなどがあり、20,000 名の情熱的な専門家が参画しています。私たちは、いつでも、どこでも、必要なときに、お客様のためにお手伝いいたします。当社のグローバル・パートナー・ネットワークは、認定設計者、設置者、インテグレーターがネットワークを前進させ続けることを保証します。





1 デジタルトレンド 2020;thenextweb.com
2 ハイパースケールの黄金時代;Data Centre マガジン;2020年11月30日
3 https://attom.tech/wp-content/uploads/2019/07/TIA_Position_Paper_Edge_Data_Centers.pdf
4 https://www.broadcom.com/blog/switch-phy-and-electro-optics-solutions-accelerate-100g-200g-400g-800g-deployments
5 倉庫規模の機械を設計するコンピュータとしてのデータセンター 第 3 版、Luiz André Barroso、Urs Hölzle、Parthasarathy Ranganathan Google LLC。Morgan & Claypool 出版社 27 ページ
6 ARPA-E 会議用 LightCounting プレゼンテーション - 2019年10月.pdf(energy.gov)
7 http://www.qsfp-dd.com/wp-content/uploads/2021/05/QSFP-DD-Hardware-Rev6.0.pdf
8 https://osfpmsa.org/assets/pdf/OSFP_Module_Specification_Rev3_0.pdf
9 Andy Bechtolsheim、Arista、OFC '21